

Aston Martin F1 Partnership
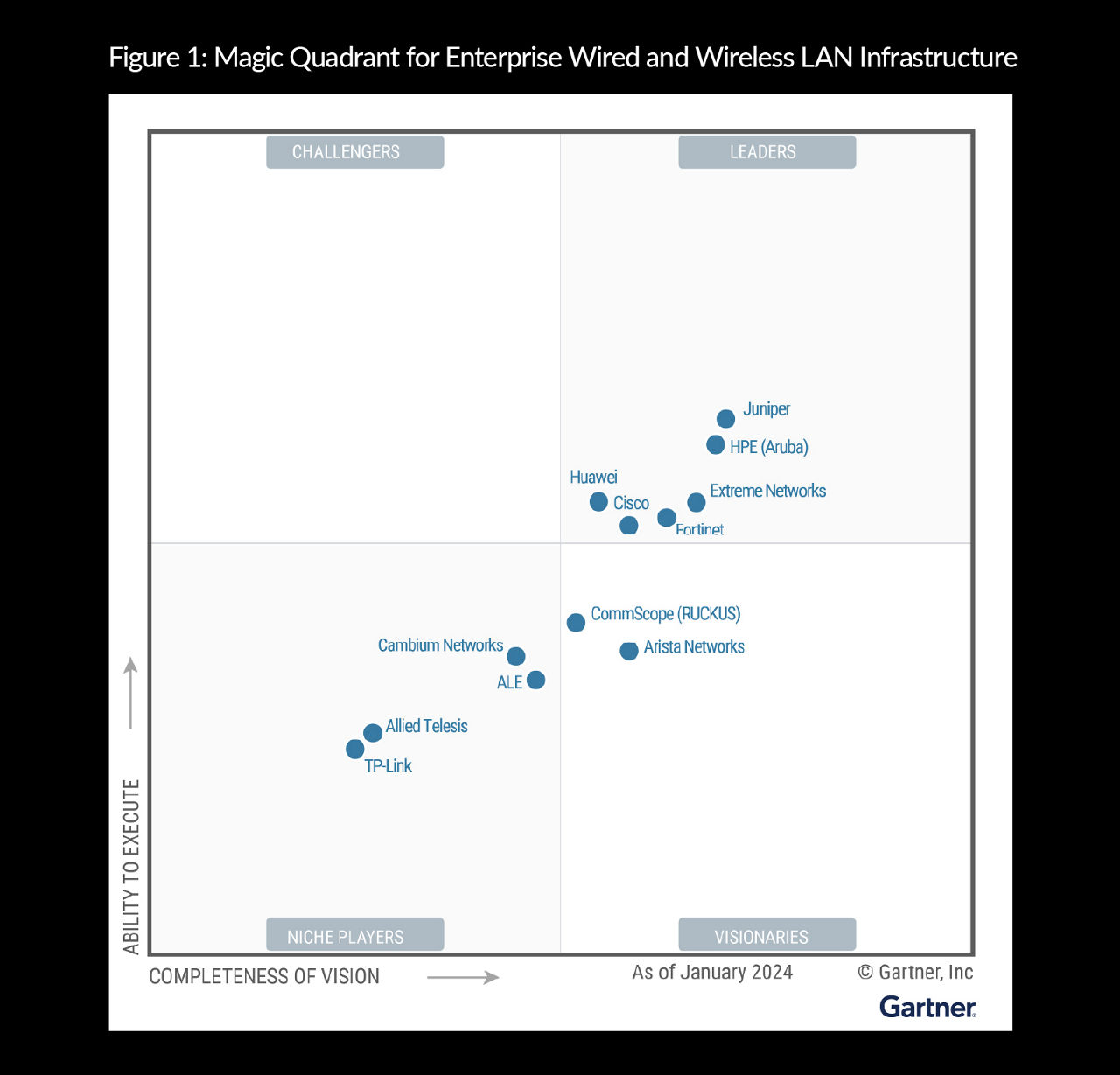
4x Leader in Wired and Wireless
Watch AI-Native NOW on-demand
Mobile World Congress 2024 Keynote with Rami Rahim
Watch the MWC24 keynote where Rami Rahim, CEO of Juniper Networks and Antonio Neri, President and CEO of HPE, discuss why the unprecedented technology shift spurred by AI will change the game in the networking industry.

Introducing the AI-Native Networking Platform
Our AI-Native Networking Platform delivers the industry’s only true AIOps with unparalleled assurance in a common cloud, end-to-end across the entire network. You can rely on it to significantly streamline ongoing management challenges while assuring that every connection is reliable, measurable, and secure. Or build highly performant and adaptive network infrastructures that are optimized for the connectivity, data volume, and speed requirements of mission-critical AI workloads.

Get networking and cybersecurity solutions that deliver real business results.
IT Teams
Put experience first.
The most important requirement for networking is simple: great experiences. Juniper delivers the insight, automation, and assurance needed for the best operator and end user experiences from client to cloud.

Service Providers
Transform your customer experience.
Take an innovative, automated, experience-first approach to your infrastructure, operations, and managed services. Our solutions put your experience as a network operator and the service experience of your customers first, helping your business stay agile, competitive, and secure in a rapidly changing economy.

Cloud Operators
Deliver an exceptional experience at cloud scale.
Drive innovation while providing the performance and agility your customers expect. Our cloud solutions help you deliver applications and services efficiently and securely—at cloud scale.

Happy customers, real results
Discover how our customers are transforming the way people connect, work, and live.
30
/30World's top service providers run on Juniper
8
/10Leading retailers create stellar experiences with our products
20
/20Top cloud operators scale with our solutions
10
/10of Forbes top global companies
30
/30of the world’s largest cloud providers
40
/40of global top Service Providers
18
/20of the most prominent universities globally
18
/20of the largest global banks
8
/10of top global retailers






Juniper in the News

Juniper Networks Unveils Industry's First AI-Native Networking Platform to Deliver Exceptional User Experiences and Lower Operational Costs
Juniper Networks, the leader in AI-networking for exceptional user and operator experiences, today announced the first AI-Native Networking Platform that leverages a common Virtual Network Assistant (Marvis).

The next level of self-driving network optimization is here: Meet Marvis Minis
In networks, as in many facets of life, people have long accepted reactive responses to issues as the best we can do. Take healthcare, for example. You get sick, you go to the doctor, and you get treated. When it comes to networking...

HPE to Acquire Juniper Networks for $14 billion
Hewlett Packard Enterprise said it’s agreed to buy networking gear vendor Juniper Networks for about $14 billion, or $40 per share, in an all-cash deal.

Juniper Networks Stock Surges on Possible HPE Takeover
Shares in Juniper Networks (JNPR) surged Tuesday, putting the stock on pace for its strongest day in decades, after The Wall Street Journal reported that Hewlett Packard Enterprise (HPE) was in advanced talks to buy the networking company for about $13 billion.
Experience Juniper for Yourself
The Rise of AI in AI-Native Networking
Discover the future of networking with Juniper's Chief AI Officer, Bob Friday, as he delves into the essence of an AI-Native platform. Learn how Juniper's innovative approach, building AI solutions on a real-time cloud foundation, sets a new standard for network users and operators.

What is AI-Native Networking?
"AI-Native" refers to a design philosophy or approach where Artificial Intelligence (AI) is deeply integrated into the core architecture of a system or solution from the outset, rather than being…
Seagate Selects our AI Enterprise Solution
Seagate Technology® selected Juniper’s full stack AI-driven enterprise portfolio to support evolving business needs and gain proactive client-to-cloud insight, optimized performance, and cost savings.
What is Artificial Intelligence for Networking?
Learn how artificial intelligence (AI) plays a key role in modern networking. Technologies such as machine learning (ML) & deep learning (DL) contribute to important outcomes, including lower IT costs & delivering the best possible IT & user experiences.

Access to networking experts and ideas
The best streaming content from Juniper's executives, experts, and events to help you shape experience-first networks.
Juniper Global Sites
Visit us any time:
Gartner Magic Quadrant for Enterprise Wired and Wireless LAN Infrastructure, Tim Zimmerman, Christian Canales, et al., 6 March 2024
Gartner, Magic Quadrant for Indoor Location Services, Tim Zimmerman, Annette Zimmermann, Nick Jones, 28 February 2024
GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally, and MAGIC QUADRANT is a registered trademark of Gartner, Inc. and/or its affiliates and are used herein with permission. All rights reserved.
This graphic was published by Gartner, Inc. as part of a larger research document and should be evaluated in the context of the entire document. The Gartner document is available upon request from Juniper Networks.
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
Juniper Networks is recognized as Juniper in the 2024, 2022, and 2021 Magic Quadrant for Enterprise Wired and Wireless LAN Infrastructure reports
